综述
并发编程大概有3种不同的实现方法。
-
进程
-
IO多路复用
-
线程
这三种方法各有优缺点。 对于进程来说,进程拥有独立的地址空间,但是进程之间通信需要用IPC,较为不便。 IO多路复用其实只有一个进程,但是在这一个进程里面,拥有一个状态机,根据不同的IO到达的状态,执行不同的逻辑,从而实现并发。IO多路复用里面的控制流不会被系统调度,而且自身根据状态调度。 线程结合了IO多路复用和进程的特点,一个进程可以包含多个线程,这多个线程共享同一个地址空间,这方便了线程之间的通信,同时线程也可以像进程一样被系统调度。
关于接下来的讨论
为什么要实现并发呢?我们考虑这样一个例子:一个HTTP服务器,当客户端连接到HTTP服务器后,客户端发送一些数据,服务器返回对应的信息。
如果没有并发,那么服务器只能实时的“照顾一位顾客”,当有第二位顾客到来,服务器边只能暂时搁置第二位顾客。
这显然是不能接受的,所以我们要实现“并发”,让服务器可以在一段时间内,同时照顾着多个顾客。注意这里我们用的是一段时间来描述,因为并发不要求在一个时刻同时服务多个顾客,而只要在一段时间内同时照顾到这多个顾客即可。对应的,如果使用一个时刻这个词的话,我们的描述应该是“并行”,也就是 parallel ,对应的可能有多个服务员,来实现并行。
为了实现并行,大致有上面刚刚说到的3个方案。下面就来详细的探讨一下
使用进程实现并发
进程是大家都相当熟悉的,在linux下面使用fork创建一个进程,之后系统就会对不同的进程进行调度。这是内核自动完成的,不需要我们手动的干预,每个进程就像是一个虚拟的小人一样,只不过这个小人一会儿运动,一会儿不运动。但是只要运动的时间间隔够小,你就感受不到他是“虚拟的”。
对于每个进程来说,他们都有着自己独立的虚拟内存空间。这既是优点也是缺点:
-
优点在于
-
独立的地址空间,可以消除不同进程之间的奇奇怪怪的冲突。
-
-
缺点在于
-
需要使用IPC进行进程间通信,这通常来说是比较慢速的。
-
同时,进程的调度消耗也是比较大的。
示例代码如下:

注意第33行,他在主进程里面关掉了connfd这个文件描述符,这主要是因为子进程和父进程之间共享同一个文件描述表。所以父进程和子进程都需要关闭这个文件描述符,以防止内存泄露,关于这点需要详细的了解一下系统IO。
使用IO多路复用实现并发
我们来考虑一下进程的缺点。
首先,进程很占资源,无论是进程之间的调度,还是进程占用的内存,对系统都是一笔不小的开销。当客户太多之后,如果每个客户都要一个服务员的“影分身”,那么服务员很可能就先挂了,他不能分出太多的分身。那么有什么办法可以改善这个情况吗?
考虑一下,服务员的每个影分身都在干什么:当一个客户到达餐馆后,客户并不是时时刻刻都需要和服务员交流。也就是说,大部分时间,我们的“影分身”都在等待客户,这就是IO阻塞。
基于以上特点,我们能不能用一个服务员就满足多个客户的需求呢?当然是可以的。
当每个客户进入饭店后,服务员都安排他们坐下,当客户点好餐后,客户举手,这时候服务员就会看到客户,然后到他跟前处理一下,接着看下面有没有举手的,如果有新的举手的,就继续处理。
这其实是一种事件驱动模型,客户举手或者新客户到达,都是一个“事件”。
事实上,现在很多的高性能服务器,例如NodeJs Nginx等,都使用事件驱动的编程方法,内涵思想就是IO多路复用,为什么呢?主要就是因为他具有巨大的性能优势。
总结一下优点和缺点:
优点
-
速度快
-
因为在单个进程中,数据易于共享。
-
易于调试
缺点
-
写代码复杂
-
进程可能阻塞
-
无法利用多核处理器
考虑下第二个缺点,进程可能阻塞,这是什么意思呢?我们知道事件驱动模型、IO多路复用的服务器是通常是运行在单个进程上的。这意味着一旦阻塞,这个进程上的所有客户都将被搁置。 假如有一个恶意的顾客,来到饭馆举手,把服务员钓来之后,一直支支吾吾不说清楚,这是不是耽误了其他顾客呢?
对于这个问题,可以使用非阻塞IO来解决
关于阻塞IO、同步、异步、非阻塞的问题需要专门写一篇文章来梳理,这里先挖个坑,以后填上。
使用线程实现并发
特点
前面说了两个实现并发的方法。
第一个:进程,由系统进行调度,不同程序流之间的地址是互相独立的,各自拥有虚拟地址,但是开销较大,进程之间数据交换较为困难。
第二个:IO多路复用,在一个进程里面,根据IO的状态执行不同的控制流,实现并发。
下面要说的线程,就结合了上面两种方法的特点:线程可以被系统所调度、同时在同一个进程下的不同线程可以共享一个地址空间、共享一些数据。

线程的上下文比进程的上下文要小的很多,这是为什么呢。主要的问题在于进程需要管理系统分配的资源、内存等,而线程是共享进程的资源,自己只需要关注和自己运行逻辑相关的堆栈、寄存器切换就可以。
这里有一个问题,切换进程的时候,cache怎么办。这里再挖个坑。
线程当中的一个小坑:
考虑如下一段程序,开启线程的时候,把参数的指针传入线程,线程中再从这个地址取出参数。这有什么问题吗?
问题很大,主要在于线程与线程之间的运行顺序是未知的,当我们传入一个地址后,如果地址上的内容改变,然后子线程再被调度,那么子线程就收到了一个错误的参数,所以我们必须保护这个参数的地址在子线程取出参数前不受其他线程的干扰,可以考虑单独给这个参数malloc一个空间。
Nginx vs. Apache
Apache使用的是阻塞IO+多线程模型
Nginx使用的是非阻塞IO+IO多路复用模型
所以Nginx更是个处理大量的并发操作。值得注意的是,Nginx其实是多线程+每个线程IO多路复用,这其实结合了上面两种思想。这样就可以既利用多核心,同时保证高并发。
线程的内存模型
线程共享同一个虚拟内存,这更易于共享数据,但也容易带来一些疑惑,哪些内存是共享的,哪些内存是线程独有的呢?
对于线程来说,每个线程都有自己独立的:线程ID、栈、栈指针、PC指针、条件码、通用寄存器。
但在一个进程中的线程全部共享这个进程的上下文,这包括read-only text(CODE区)、可读写数据、堆、共享库的代码和数据区、打开的文件。
寄存器是永远不共享的,但虚拟内存区域总是共享的
这意味着,虽然每个线程都有各自的stack,但他们是没有保护,也就是说,如果你有一个线程的栈区域内存指针,那么你可以在另一个线程中使用指针去访问这个地址的数据。
变量在内存中的区域
c语言中,变量有多个类型,根据他们的存储类型,映射到虚拟内存中
-
全局变量
全局变量是声明在函数外的变量,被存储在虚拟内存的读写数据区,可以被同个进程中任意线程引用。
-
局部变量
声明在函数内、没有static关键字。在运行的时候,每个线程的stack包含一个变量的实例
-
局部静态变量
函数内声明,但使用static关键字,即使有多个线程运行,他们也只有一个实例存在,放在和全局变量一样的地方。
信号量同步线程
虽然不同线程之间共享变量很方便,但如果两个线程错误同时访问了两个变量,就可能产生错误。

考虑以上程序,会出什么问题呢,不就是共享了一个cnt而且两个线程一直++吗,这看起来没啥问题啊,你加一,我加一,一起快乐做游戏。
其实问题就在于,我们的思维上,cnt++这个操作是一个整体,但实际运行中,cnt++这个操作是分离的。
主要分为Load Update Save三个步骤,那么这就不是一个整体的操作了,显然在这种分散操作的情况下,就容易出现共享变量出错。
用CSAPP中的线程图来解释:
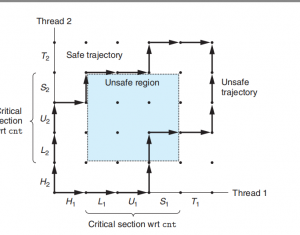
两个线程陷入了不安全区域
那么如何让他们协同工作呢?
很简单,只要让cnt++变成原子操作,即当某个线程进入L U S这个步骤之后,其他的线程不得干扰,必须等待该线程操作完成。
下面就借助信号量实现线程之间的同步协同:
信号量
Djikstra是并发编程的先驱,是他首先提出了信号量解决同步问题的方案。信号量是一个变量,是一个非负整数,仅仅只能被两个操作所访问:P、V
P(s):如果s是非零的,那么s–,并且立即返回。如果s是0,那么暂停这个线程直到s变成非0;
V(s):s++
P和V的操作必须是原子的,也就是不可分离的,原子操作的底层实现依赖于硬件提供的硬件接口。

使用如图的顺序,在cnt前后用PV保护起来,即可实现只有一个线程可以访问这个区域:
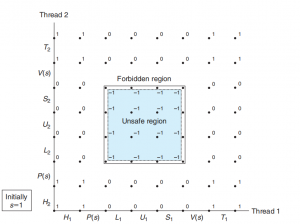
这种只允许0-1的信号量,称为二元信号量,以互斥为目的的二元信号量常称为互斥锁(mutex)
生产者消费者问题
生产者消费者很常见,我们常用的事件循环模型就是典型的生产者消费者。
这里打算再写另外一个文章来描述这个典型的例子
同步操作的开销是非常巨大的,所以需要尽量避免在许多个线程中同时访问共享变量,尽量使用局部变量。
以下这些问题都相当关键,另开文章来写