为了锻炼英语水平,这篇笔记用英文记录
what is virtual memory? why we need it?Today, I want to talk about it and record somethings in this blog for comprehending batter.
First and foremost,What is Virtual Memory?
What is Virtual Memory(Basic Concept Of Virtual Memory)
In the model Operating System, we can run a lot of program, and the memory of every program is individual. The processes run on machine have a Virtual Space and the Virtual Space seems infinite and exclusive. This is what the Virtual memory do in model Operating system.
So now, We know that Virtual Memory is the tools in Operating System to help we to run multiple program.
Physical and Virtual Addressing
Physical Addressing
The main memory is organized as an array of M contiguous byte-size cells. Each cell has a unique address known as Physical Address. The most natural way for a CPU to access memory would be to use Physical Addressing
Virtual Addressing
With virtual addressing, the CPU accesses memory by virtual address(VA), which is converted to the physical address before being sent to main memory (address translation) .
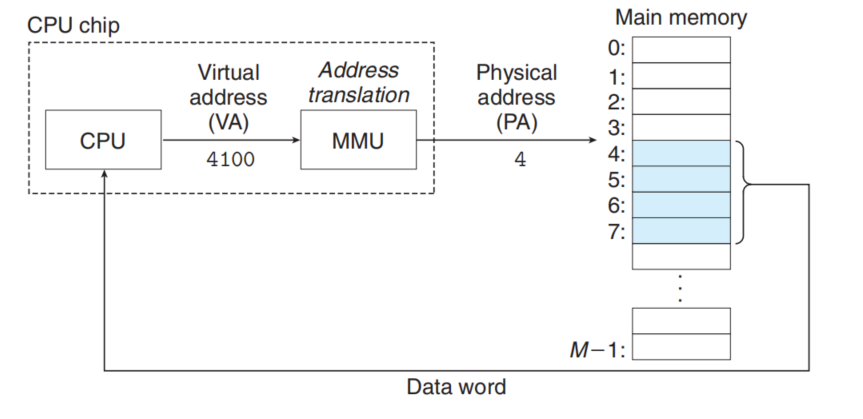
Address translation is a collaborative work which is done by the Hardware and Operating System.
The hardware called the memory management unit(MMU). MMU lookup table stored in main memory whose contents are managed by operating System.
Why we need it.()
In general, we need the Virtual memory for three reasons:
-
make the main memory efficient by treating it as cache for an address space stored on disk.(Caching)
-
It simplifies memory management by providing each process with a uniform address space.(Management)
-
It protects the address space of each process from corruption by other processes.(Protection)
#
VM as Tool for Caching
Partition
At first, we think of memory as a kind of cache between disk and cpu. The CPU can run by get command and data from disk, but the access time of disk is very large. We need the DRAM to cache the code and data.
We partition the data as the transfer units between the disk and main memory.
The transfer units known as Virtual Pages(VPs) in Virtual Memory.(Virtual Memory stored in disk)
The transfer units known as Physical pages(PPs) or Page frames.(Caching in Main memory)
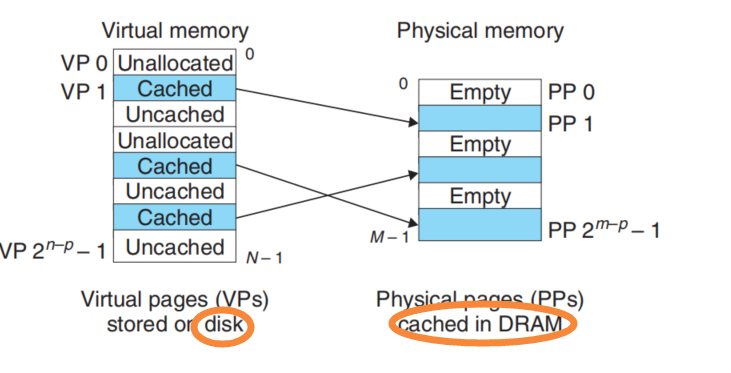
This concept is similar as SRAM Caching. But the DRAM Caching need bigger Pages is transfer units because the First Access Time of disk is so large. The cost of reading the first byte from disk sector is about 100000 times slower than reading successive bytes in sector.
Page Table
When we access an address of Virtual Memory, we want to know if it cached. If the answer is yes, we need to get the Physical address of the Virtual address and access DRAM-CACHE to get the data. So we need a Table(Page Table) to record the information about if the VM is cached and the corresponding address(Physical Address).
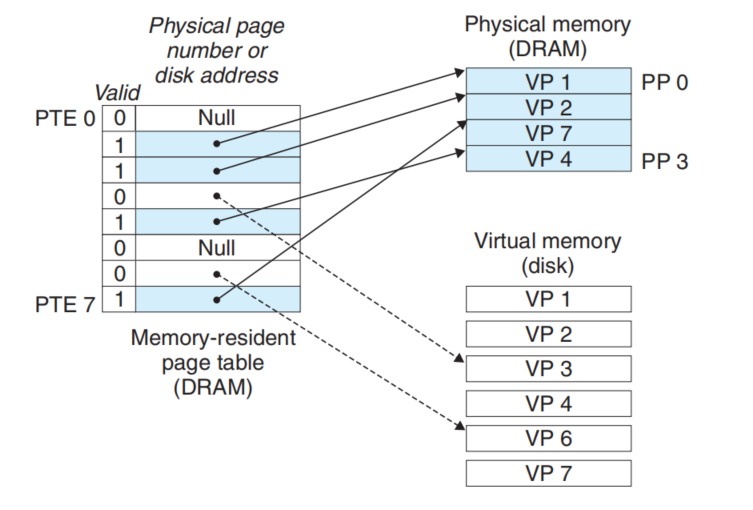
The structure of page table like this.
When we access the address X(also in the X-th page), we just to find the X-th Item of the table and check the information to decide next step.
If the valid is 1, the machine can get the PA and access the DRAM-CACHE.
If the valid is 0, the machine will run a Page Fault handler in System kernel, which selects a victim page. If the victim has been modified, then the kernel copies it back to disk. In either case, the kernel modifies the page table Entity for the victim page to reflect the fact that victim is no longer cached in DRAM-CACHE. Next, kernel copies the VP we accessing to DRAM-CACHE and update the Page Table.(If the Cache Space is enough, we don’t need to select the victim)
VM as Tool for Memory Management
Separate Virtual Space for every process has a profound impact on the Memory Management. VM simplifies linking and loading, the sharing of code and data, and allocating memory to applications.
-
Simplifying Linking
A separate and virtual address space allow each process to use the same basic format for its memory image, regardless of where the code and data actually reside in physical memory.
-
Simplifying Loading
Linux Loader just allocates virtual pages for the code and data segments. Then Loader points the Address of Page Table for the process.
Loader never actually copies any data from disk into memory cache. The data are paged in automatically and on demand by the virtual memory system the first time each page is referenced.
-
Simplifying Sharing

-
Simplifying Allocating
When a program running in a user process requests additional heap space, operating system just allocates some virtual page for process. And operating system don’t need to decide where the page should be cached in Memory.
VM as Tool for Memory Protection
It’s easy to prohibit that process access private data of another process for the separate address space of VM system.
Program accessing of memory must via the address translation, so we just need to add some flag into page Table Entity that the protection system could be built up.

Address Translation
There are the details about address translation
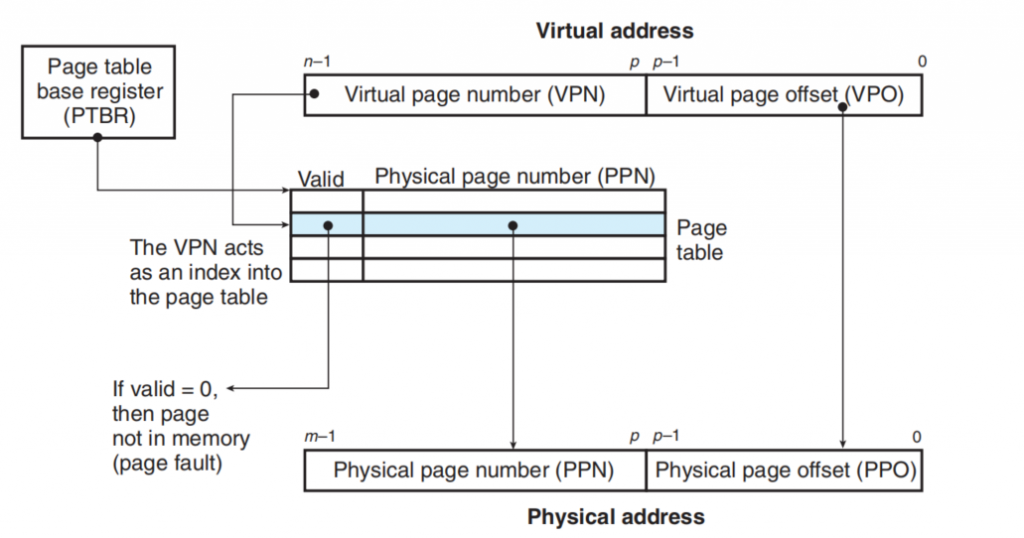
This figure show How the address translation work.
VPO is identical to the VPO, both they are compose of p bit . When we access a VP, CPU find the correct Page Table Entity and the Page Table Start Address is stored in PTBR(A register in CPU).
If the Valid is 1, that means page hit.
-
Processor access a Virtual Address and The VP sends to MMU
-
MMU requests the correct PTE from the Main Memory/Cache
-
The cache/Memory return PTE
-
MMU get correct Physical Address and sends it to the cache/Memory
-
cache/Memory return data.
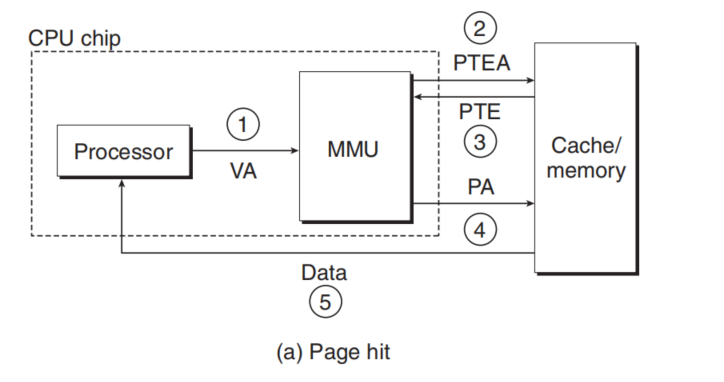
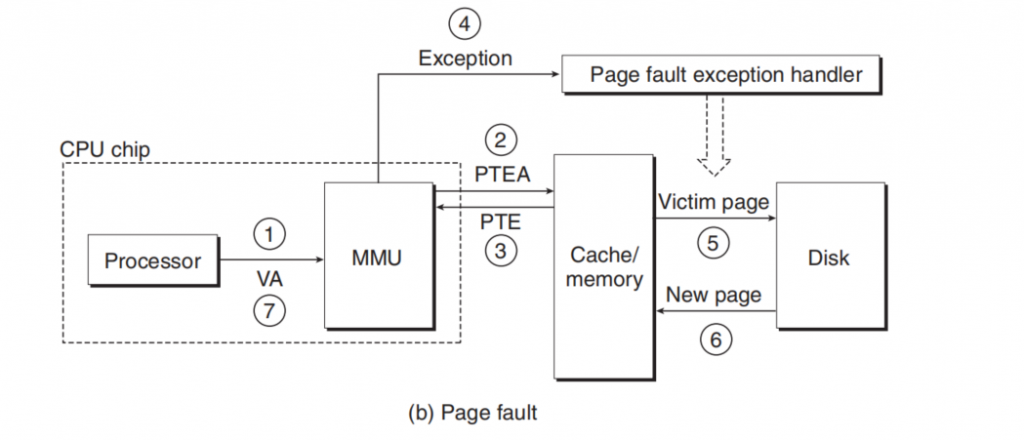
If the Vaild is 0.
-
-3. same as above
-
The MMU triggers an exception(Page Fault Exception)
-
The fault handler identifies a victim page in Physical Memory,and if the page has been modified, pages it out to disk.
-
The handler page in the new page and update Page Table.
-
The handler returns to the original process and re-execute the instruction.
Cache the Page Table Entity (TLB)
Each time when we access the memory looking for data or some other things, we must access Physical Memory two times(for Getting PTE and Getting Data).So someone proposes a idea that we can cache the PTE into a faster place then we would get faster when transferring address. This is the origin of TLB.


Save Memory(Multi-Leave Page Tables)
if we had a 32-bit address space, 4 KB pages, and a 4-byte PTE, then we would need a 4 MB page table resident in memory at all times, even if the application referenced only a small chunk of the virtual address space.
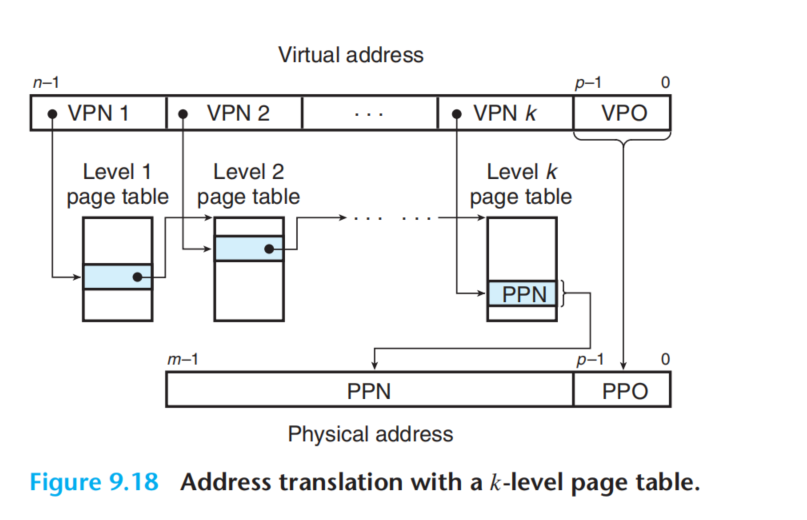
The multi-Leave Page Table solve the problem.
It’s easy to understand that we just create the page table when we use the corresponding address. So we can save a lot of space but the structure is more complex. And we must to access k PTEs. It seems expecsive but TLB come to the rescue here by caching PETs.
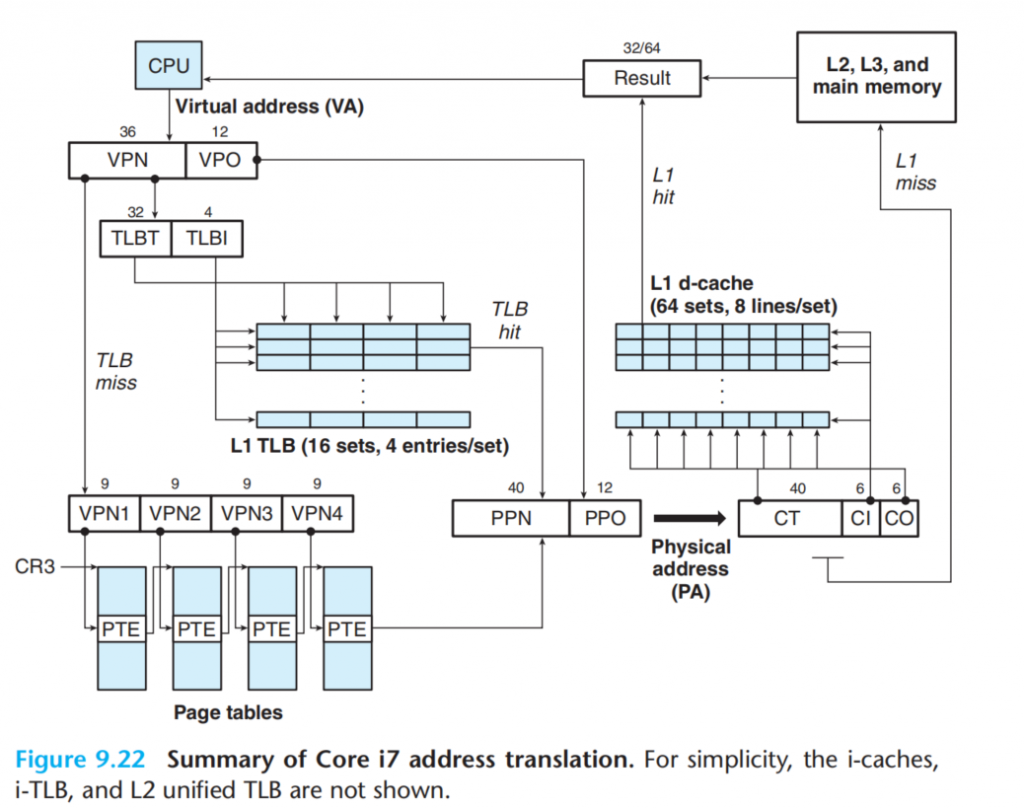
Case : Intel Core I7/Linux Memory System.